
Pilotez la qualité de vos interactions à grande échelle et sans écoute manuelle.
Feedae note chaque appel selon votre grille de critères. En temps réel, sans biais humain.
Feedae note chaque appel selon votre grille de critères. En temps réel, sans biais humain.
Le Quality Monitoring tel qu'il existait avant l'IA souffre de quatre problèmes systémiques qui se cumulent et se renforcent mutuellement.
Vous écoutez 2-5 % des appels. Les 95 % restants sont une boîte noire. Les agents le savent et adaptent leur comportement en conséquence.
Deux superviseurs, le même appel, deux scores différents. L'humeur, la fatigue, l'affinité avec l'agent influencent chaque évaluation.
Un superviseur passe en moyenne 45 minutes par évaluation manuelle. À 10 appels/semaine, c'est 7 h de son temps pour 1 % des conversations.
Le feedback arrive des jours après l'appel. L'agent ne s'en souvient plus, le client est déjà parti.

Un volume
représentatif d'appels que vous souhaitez évaluer.
La qualité
Critère par critère, Scoring IA, justification textuelle, grilles personnalisées.
Coaching ciblé et conformité continue
Insights, verbatims, Feedy notre moteur de recherche.
Feedae part de votre grille actuelle : critères binaires, ternaires ou à score, pondérations, niveaux de sévérité. Aucune refonte nécessaire. La mise en production se fait avec votre CSM en quelques jours, avec un protocole de validation sur vos appels réels.
Chaque critère est évalué avec une explication textuelle tirée du transcript, le moment exact, la phrase exacte. Le manager lit la justification en 20 secondes sans réécouter l'appel. Les cas "non applicable" sont traités explicitement, le LLM ne force jamais une réponse vide.
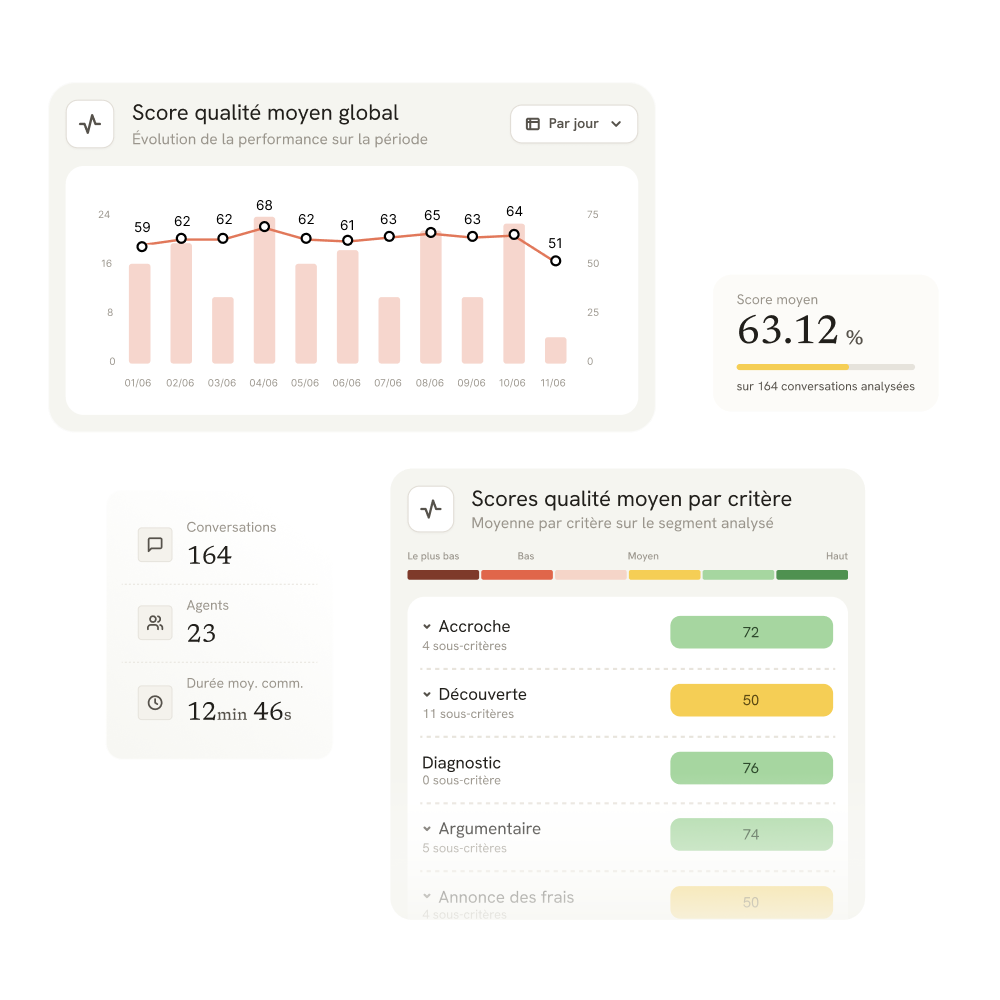
Visualisez les scores globaux, l'évolution dans le temps, le détail critère par critère et le classement par agent. Accédez directement aux conversations problématiques depuis n'importe quel critère en un clic sans revenir à la liste.
Détectez les comportements invisibles: combativité insuffisante, objections non traitées, discours non conformes, sur 100% du volume. Exportez les extraits pour vos ateliers de coaching. Interrogez Feedy en langage naturel : "Quels agents ne relancent jamais après un refus ?"
Retrouvez vos appels analysés dans une vue unifiée, filtrable par score, motif, agent ou équipe. Construisez vos grilles selon vos enjeux métier, compliance, conversion, satisfaction et laissez l'IA scorer chaque critère avec une justification textuelle. Pas des chiffres à lire, des décisions à prendre.







Questions fréquentes